Jupyter Lab
安装saspy¶
启动python,通过以下命令找到saspy配置文件的位置
例如返回
<module 'saspy' from '
/home/ubuntu/miniconda3/envs/py39/lib/python3.9/site-packages/saspy/__init__.py'>
通过SFTP打开该目录/home/ubuntu/miniconda3/envs/py39/lib/python3.9/site-packages/saspy,编辑该目录下的sascfg.py文件:

将default中的saspath改为本服务器的SAS安装位置。该安装位置可以在Linux Shell通过以下命令得到:
which sas没有任何返回值
原因
- SAS的应用程序尚未加入
PATH环境变量中。 - SAS在本服务器并未安装。
解决方案
请联系管理员安装SAS并将执行文件软链接到/usr/bin。
CFID 的用户可以直接使用 /usr/local/SASHome/SASFoundation/9.4/bin/sas_u8 这个路径。
在Python中使用¶
SAS官方提供的saspy参考代码:saspy-examples
经过尝试,目前推荐的流程如下。
初始化¶
使用SAS数据首先需要将对应的目录作为Library指示给SAS。下面的例子即是将/data/dataset/Compustat/d_global目录作为一个Library指示给SAS,并命名为db。
import saspy
sas = saspy.SASsession()
ll = sas.submit('libname db "/data/dataset/Compustat/d_global";')
读取数据¶
在此处,我们默认数据处理的核心是Pandas。因此目标是以尽可能高效的方式将SAS数据读取为Pandas.DataFrame。如果需要转换为其他数据类型,可以从Pandas.DataFrame做进一步转换或自行探索其他方案。
读取整张表:
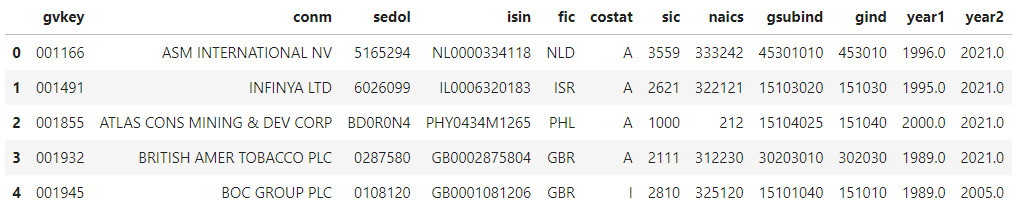
效率问题
读取大表时不建议采用这种方法,请参考下方。
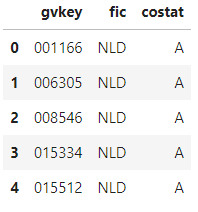
有选择地读取:
df = sas.sd2df(
libref='db',
table='g_names',
dsopts={
'where': 'costat = "A" and fic = "NLD"',
'keep': ['gvkey', 'costat', 'fic'],
# 'drop': ['conm', 'sedol'],
'obs': 10
}
)
df.head()
处理大文件
建议善用where和obs选项。先按一定条件选择少量数据观察,并写完处理代码后,再对整张表进行读取。
在数据被处理达到合理大小后,可以及时存储为Parquet格式。方便快速调用查询结果。
读取大表尽量不要覆盖SAS直接返回的变量(上面例子中的df),否则每次处理出问题都需要重新读取的话会比较浪费时间。90GB的SAS数据读取一遍大约需要10分钟。
更多选项请参考帮助文档和样例代码。
进阶查询¶
选择所有与列表中元素可以匹配的数据
df = sas.sd2df(
libref='db',
table='g_names',
dsopts={
'where': f'gvkey IN ({",".join([str(int(i)) for i gvkeys])})',
}
)
df.head()
在 WHERE 语句中按日期查询